RNN+LSTM
Why we need RNN?
普通的神经网络虽然强大,但是只能单独的去处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
以nlp的一个最简单词性标注任务来说,将我 吃 苹果 三个单词标注词性为 我/nn 吃/v 苹果/nn。
这个任务的输入是:我 吃 苹果 (已经分词好的句子)
这个任务的输出是:我/nn 吃/v 苹果/nn (词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
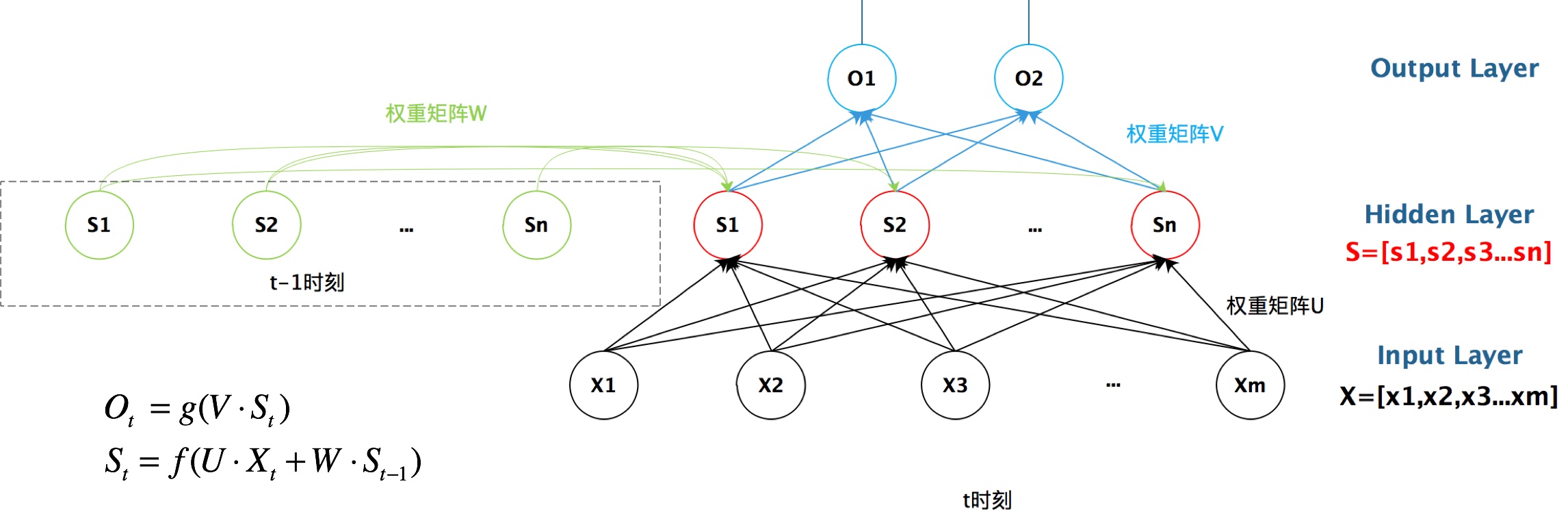
RNN的结构
循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
LSTM
RNN功能这么强大,那么LSTM又是干什么的呢?
RNN 是在有顺序的数据上进行学习的. 为了记住这些数据, RNN 会像人一样产生对先前发生事件的记忆。
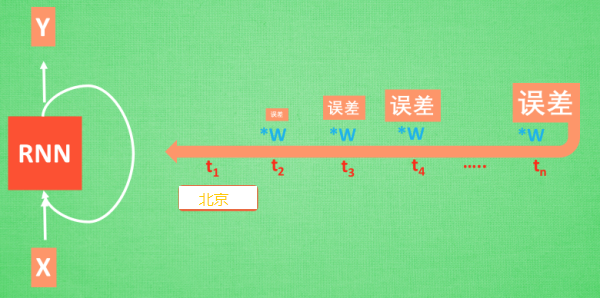
想像现在有这样一个 RNN, 他的输入值是一句话: “我今天要去北京旅游, 首先我要坐大巴去机场,然后登上飞机,经过漫长的旅途,就到站啦。”那么用 RNN 来分析, 我今天去了什么地方呢? RNN可能会给出“菏泽”这个答案。因为结论出错, RNN就要开始学习这么长一段话和 “北京“的关系 , 而RNN需要的关键信息 ”北京”却出现在句子开头。
”北京“这个信息的记忆要进过长途跋涉才能抵达最后一个时间点,然后我们得到误差。而且在反向传递得到的误差的时候,他在每一步都会乘以一个自己的参数 W。如果这个 W 是一个小于1的数, 比如0.9。这个0.9不断乘以误差, 误差传到初始时间点也会是一个接近于零的数, 所以对于初始时刻, 误差相当于就消失了。我们把这个问题叫做梯度消失或者梯度弥散。
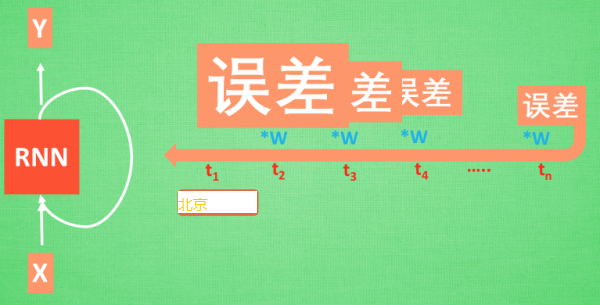
反之如果 W 是一个大于1的数,比如1.1。不断累乘,则到最后变成了无穷大的数,RNN被这无穷大的数撑死了, 这种情况我们叫做梯度爆炸。 这就是普通 RNN 没有办法回忆起久远记忆的原因。
LSTM 就是为了解决这个问题而诞生的。LSTM 和普通 RNN 相比,多出了三个控制器(输入控制,输出控制,忘记控制)。现在, LSTM内部的情况是这样:
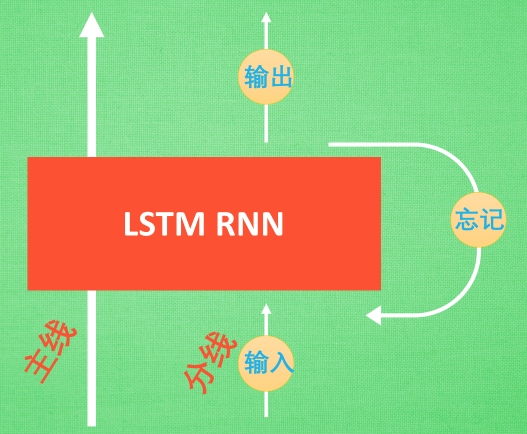
多了一个控制全局的记忆, 我们用粗线代替.。输入控制,输出控制,忘记控制三个控制器都是在原始的 RNN 体系上, 我们先看输入方面 , 如果此时的分线剧情对于剧终结果十分重要, 输入控制就会将这个分线剧情按重要程度写入主线剧情进行分析. 再看忘记方面, 如果此时的分线剧情更改了我们对之前剧情的想法, 那么忘记控制就会将之前的某些主线剧情忘记, 按比例替换成现在的新剧情。所以主线剧情的更新就取决于输入和忘记 控制。最后的输出方面, 输出控制会基于目前的主线剧情和分线剧情判断要输出的到底是什么。基于这些控制机制, LSTM就可以带来更好的结果。